1. Entstehung
Die Ursprünge des Katasters gehen in die frühen 90er Jahre zurück. Mit der Einführung von Einzelplatz-PCs sollte die bis dahin im Einsatz befindliche Großrechneranwendung Uschi (Umweltschutzinformationssystem) abgelöst werden. Angestrebt war eine Lösung mit Informix als Datenbank und Frontends, die in Smalltalk programmiert waren. Aufgrund verschiedenster Unzulänglichkeiten konnte sich diese Programmierung jedoch bei den Anwendern und Anwenderinnen nicht durchsetzen.
Da die PCs aber mittlerweile mit MS-Access ausgestattet waren, begannen zahlreiche Sachbearbeiter und Sachbearbeiterinnen für ihre Probleme individuelle Lösungen zu schaffen. Diese wurden Mitte der 90er Jahre auf Basis von Access zu einer Datenbank zusammengeführt. Um eine ausreichende Sicherheit der Daten zu gewährleisten, wurden die Tabellen bald auf ein mehrbenutzerfähiges Backend übertragen. Hierfür wurde zunächst eine DB2 und später eine Informix Datenbank eingesetzt.
Im Jahre 2005 wurden die Frontends auf Java portiert und seit 2011 liegen unsere Daten in einer PostgreSQL[1] Datenbank.
2. Aufgaben
Das Kataster soll schnell einen möglichst umfassenden Überblick über alle umweltrelevanten Anlagen an einem Standort bieten. Zudem soll es auch einen fach- und organisationsübergreifenden Informationsaustausch ermöglichen. Details aus der Sachbearbeitung werden sicher noch eine ganze Zeit in Hausakten abgelegt, aber die grundlegenden Daten der Bearbeitung werden auch über Abteilungsgrenzen hinweg bereitgestellt.
 Für die Wartung und Funktionskontrolle von Lager- oder Produktionsanlagen müssen oft Fristen von mehreren Jahren nachgehalten werden. Dies ist bei einer großen Anzahl von Anlagen nur noch über ein EDV gestütztes System möglich.
Für die Wartung und Funktionskontrolle von Lager- oder Produktionsanlagen müssen oft Fristen von mehreren Jahren nachgehalten werden. Dies ist bei einer großen Anzahl von Anlagen nur noch über ein EDV gestütztes System möglich.
Die Vergangenheit hat gezeigt, dass oft erst nach Jahren eine Belastung auf einem Standort festgestellt wird. In diesem Fall kann der Verursacher oft nur schwer oder gar nicht mehr ermittelt werden. Daher ist es wünschenswert, die Entwicklung eines Standortes möglichst vollständig dokumentiert zu haben. Nur auf diese Weise kann man Verunreinigungen einem Verursacher zuordnen, auch wenn dieser schon lange den Standort verlassen hat.
Eine weitere wichtige Aufgabe des Katasters besteht in der Erstellung von statistischen Auswertungen. Diese werden immer wieder und immer öfter von stadtinternen Stellen, aber auch von vorgesetzten Dienststellen angefordert.
In der derzeitigen Form verwenden wir das Programm für die Überwachung von Indirekteinleitern, also Firmen, die Abwasser mit gefährlichen Stoffen in den Kanal einleiten, und Anlagen, in denen mit wassergefährdenden Stoffen umgegangen wird. Ein Ausbau auf andere Bereiche ist nicht konkret geplant, durch die modulare Struktur aber jederzeit möglich. In dem Kataster können Informationen zu Objekten gespeichert werden, die über einen Standort, einen Betreiber und eine Objektart definiert sind. In der einfachsten Form muss lediglich eine neue Objektart angelegt werden, und die neuen Objekte können mit einem Minimum an Informationen erfasst werden. Sollen weitere Details gespeichert werden, geht dies über eine zusätzliche Fachdatentabelle und weitere Bearbeitungs- und Auswertungsmasken.
Um einen möglichst großen Nutzen zu erreichen, ist es wichtig, dass die Daten, wenn es möglich ist, automatisch importiert werden. Dies haben wir beispielsweise im Bereich der Probenahmen realisiert, wo ein vollständiger Workflow in dem System entstanden ist. Dieser beginnt beim Erstellen eines Probenahmeauftrags über den Import der Ergebnisse und die Freigabe der Daten und geht bis hin zum Erstellen eines Gebührenbescheides und der Übergabe einer Textdatei an die Stadtkasse.
3. Programmierung
Wie bereits erwähnt, sind die Frontends in Java programmiert. Für eine ansprechende Optik sorgen die Jgoodies[2] und als Persistenzschicht übernimmt Hibernate[3] die Kommunikation zwischen dem Frontend und den Datenbanktabellen. Hierdurch wird die Programmierung vereinfacht und ein Wechsel des Datenbank Backends ist recht einfach möglich. Grafische Auswertungen von Messdaten machen wir mit JFreeChart[4] und für die Ausgabe von PDF-Dokumenten bis hin zur automatischen Erstellung von Gebührenbescheiden für Abwasserproben nach Entwässerungssatzung kommt Jasper[5] zum Einsatz.
Von allen eingesetzten Komponenten wurden nur die als OpenSource verfügbaren Varianten verwendet, und auch unsere eigene Programmierung haben wir unter einer GPL-Lizenz freigeben.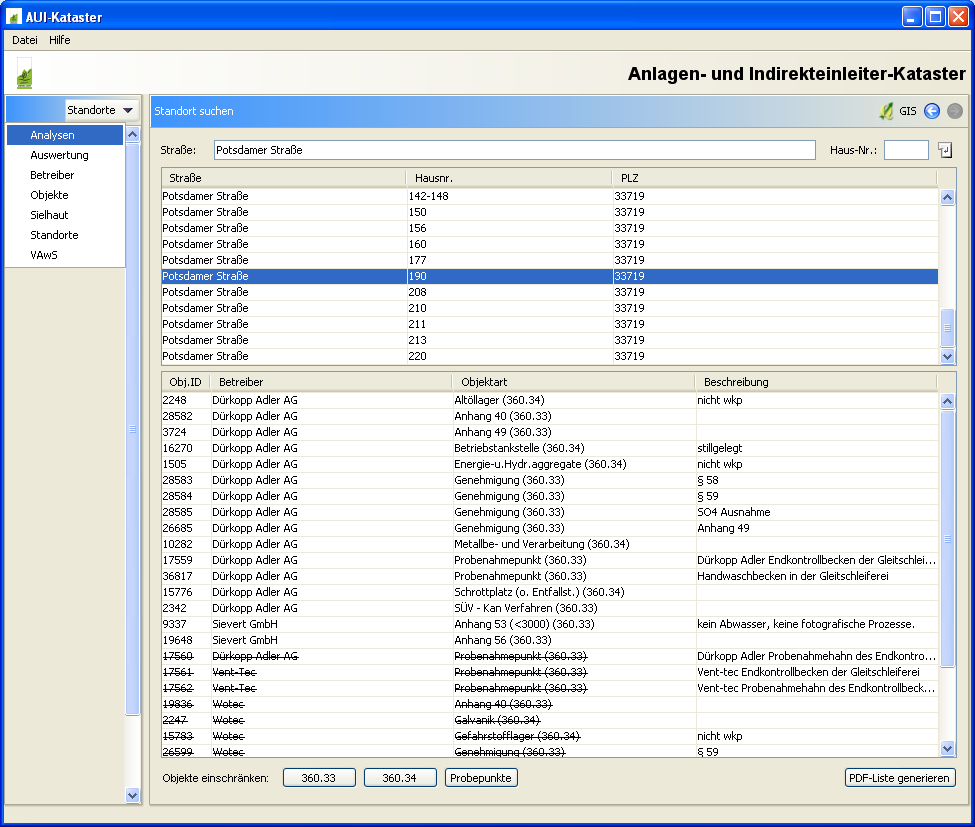
4. Bedienung
Beim Start des Programms öffnet sich nach der Authentifizierung ein Fenster zum Suchen eines Standortes, da dies der häufigste Einstieg in die Bearbeitung ist.
Wenn hier ein Standort ausgewählt wird, bekommt man im unteren Bereich einen Gesamtüberblick über alle erfassten Objekte. Durch Doppelklick auf ein Objekt können die weiteren Details aufgerufen werden.
Das Programm besteht aus verschiedenen Modulen, die zu Kategorien zusammengefasst sind. Das o. g. Modul „Standort suchen“ befindet sich z. B. in der Kategorie „Betriebe“. Weitere Kategorien sind: Auswertung, Klärschlamm, Sielhaut, Labor und VAwS (Anlagen zum Umgang mit wassergefährdenden Stoffen).
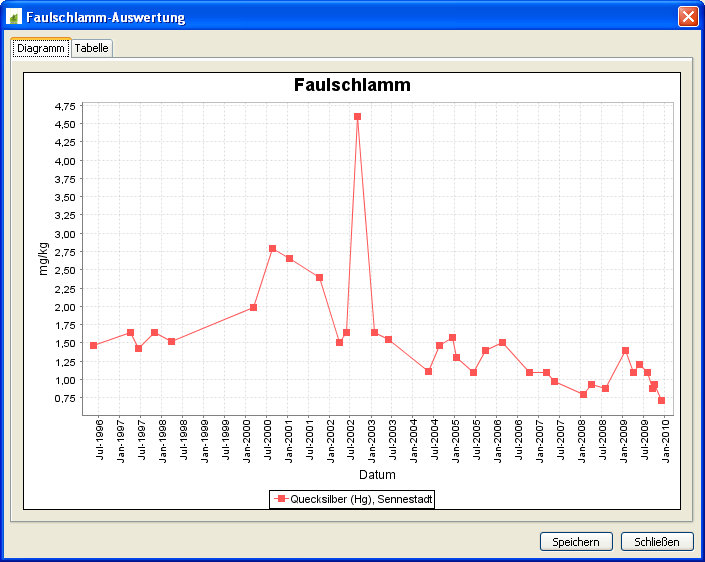
Messwerte sind in dem System zu Abwasser-, Klärschlamm- und Sielhautuntersuchungen (dies sind Untersuchungen im Kanalnetz, die Informationen über die Qualität des Abwassers liefern) enthalten. Diese können, wie bereits oben erwähnt, automatisiert über CSV-Dateien importiert und, grafisch aufbereitet, dargestellt werden.
4. GIS Schnittstelle
Als Geoinformationssystem kommt bei der Stadt Bielefeld u. a. Quantum GIS[6] zum Einsatz. Das Programm deckt alle Anforderungen der Sachbearbeitung, bei denen es nur sehr selten um die Erfassung von Flächen geht, vollständig ab. Darüber hinaus kann es als OpenSource Produkt auf beliebig vielen Rechnern installiert werden. Um dieses Programm nun möglichst komfortabel direkt aus dem Kataster heraus nutzen zu können, wurde eine lockere Anbindung programmiert.
Diese erlaubt es, das Programm mit einem lokal gespeicherten Projekt, ausgehend von einem Standort, zu starten und den Rechts- und Hochwert eben dieses Standortes über zwei Umgebungsvariablen einem PlugIn zu übergeben, mit dem man dann dort hin navigieren kann. Umgekehrt können Rechts- und Hochwerte aus der Karte abgegriffen und über die Zwischenablage in einen Datensatz übernommen werden.
Eine weitere Möglichkeit, zu einem Standort zu navigieren, besteht über eine Programmierung, die ebenfalls von dem „zoom-to-point“ PlugIn abgeleitet wurde. Diese greift auf eine Tabelle zu, in der zu jedem Standort mit Straße und Hausnummer ein Rechts- und Hochwert hinterlegt ist. Wird hier ein Standort ausgewählt, wird der Bildausschnitt aufgrund dieser Werte dort hin verschoben.
Seit dem Umstieg auf die PostgreSQL/PostGIS Datenbank Anfang letzten Jahres, wurde diese in "fisumwelt", was für Fach-Informations-System-Umwelt steht, umbenannt. Neben dem Schema "auik", in dem die Sachdatenhaltung des Katasters stattfindet, gibt es in dieser Datenbank ein Schema "gis" für Geoinformationen. Hier sind z. B. der gesamte Kanalbestand, die Wasserschutzgebietsgrenzen, Altlastenverdachtsflächen, Zuständigkeitsbereiche usw. gespeichert. Da unser Katasteramt eine Vielfalt von Karten als WMS zur Verfügung stellt, ist es nun auch wenig geübten Benutzern und Benutzerinnen möglich, ein QGIS-Projekt mit Hintergrundkarten und Fachdatenebenen zusammen zu stellen.
Ein weiteres Schema mit dem Namen "oberflgw" ist mittlerweile hinzugekommen. Hier werden die Daten zur Bearbeitung von Einleitungen in Oberflächengewässern gespeichert. Sobald das Programm "AquaInfo", das bei uns zur Erfassung der Grundwassermessstellen, Trinkwasserbrunnen und Sondierungen eingesetzt wird, die PostgreSQL Datenbank unterstützt, werden auch diese Informationen hier abgelegt und damit über die gleiche Schnittstelle im QGIS verfügbar sein.
Durch diese Struktur sind nun auch Abfragen und Veränderungen in den Datensätzen entsprechend ihrer örtlichen Lage einfach möglich. Beispielhaft sollen hier ein select und ein update Befehl für Standorte, die in dem Sachdatenschema „auik“ gespeichert sind, nach ihrer Lage in einem Entwässerungsgebiet bzw. einem VAwS-Bezirk, die in dem „gis“ Schema liegen, genannt werden:
SELECT st.id, st.strasse, st.hausnr, st.entgebid, ent.entw_geb
FROM auik.basis_standort AS st, gis.abk_entwaesserungsgebiete AS ent
WHERE Contains ( ent.the_geom, st.the_geom ) = TRUE
AND ent.entw_geb = '1.01';
UPDATE auik.basis_standort SET wassereinzgebid = vbez.ezgb_id
FROM gis.vaws_bezirke AS vbez
WHERE Contains ( vbez.the_geom, auik.basis_standort.the_geom ) = TRUE;
Nähere Informationen erhalten Sie bei Gerd Genuit (
Quellen
[5] http://jasperforge.org/projects/jasperreports
[6] http://www.qgis.org/